Support Vector Machine¶
Support vector machine is used for binary classification tasks. We first introduce the basic linear separable case (aka. hard margin), and introduce the linear non-separable case later (aka. soft margin).
Objective¶
SVM uses a hyperplane to separate two types of points.
Fig. 84 Draw a line to separate two clusters¶
Suppose there is a hyperplane in \(p\)-dimensional space characterized by the equation
or in vector form,
Then the distance from any point \(\boldsymbol{x} \in \mathbb{R} ^p\) to this hyperplane can be shown to be
Given \(n\) points \(\boldsymbol{x} _1, \ldots, \boldsymbol{x} _n\), for those points in the same side of the hyperplane, they have the same sign of \(\boldsymbol{w} ^\top \boldsymbol{x}_i + b\). If we label the points with positive values of \(\boldsymbol{w} ^\top \boldsymbol{x}_i + b\) by \(y_i = 1\) and those with negative values by \(y_i = -1\), then the distance can be written as
- Definition (Margin)
The margin is defined as the shortest distance from a point to the hyperplane.
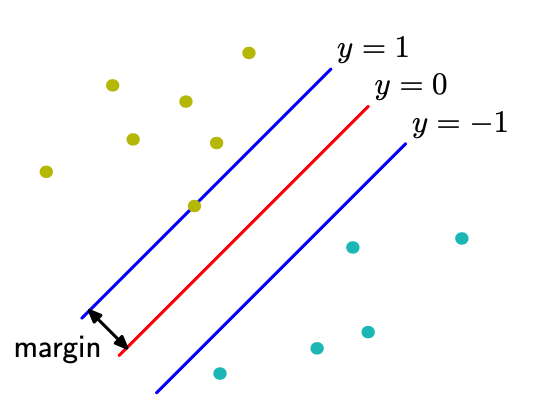
Fig. 85 Margin [Bishop]¶
The objective of SVM is to find a hyperplane \(\boldsymbol{w}^{\top} \boldsymbol{x}+b = 0\) parameterized by \(\boldsymbol{w}\) and \(b\), that separates two types of points and maximizes the margin.
i.e.,
To classify a point with coordinates \(\boldsymbol{x}\), we use the solution \(\boldsymbol{w}^*\) and \(b^*\).
If \(\boldsymbol{w}^{* \top} \boldsymbol{x} + b^* > 0\) then \(\hat{y}_i = 1\)
If \(\boldsymbol{w}^{* \top} \boldsymbol{x} + b^* < 0\) then \(\hat{y}_i = -1\)
Learning¶
We convert the optimization problem step by step such that it becomes easier to solve.
Note that distance is invariant to scaling of \(\boldsymbol{w}\) and \(b\) (or note that \(\boldsymbol{w} ^\top \boldsymbol{x} +b = 0\) and \((k\boldsymbol{w}) ^\top \boldsymbol{x} + (kb) = 0\) characterize the same hyperplane), thus we can assume \(\min _{i} y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_i + b\right)=1\)
Then the maximization-minimization problem becomes a constrained maximization problem
Or equivalently,
To get rid of the constraints on \(\boldsymbol{w}\) and \(b\), we use Lagrangian multiplier method. Let
where \(\lambda_i \ge 0\).
Then the problem becomes
Since \(\min_{\boldsymbol{w} ,b} L\) is better to solve than \(\max_{\boldsymbol{\lambda} } L\), we want to exchange the min-max order. This step is valid since it is a quadratic minimization with \(n\) linear constraints, where strong duality holds. As a result, its dual problem is
which is has the same solutions \(\boldsymbol{w}^*, b^*\) with the primal problem.
We first solve the minimization problem. Taking derivatives of \(\mathcal{L}\) w.r.t. \(\boldsymbol{w} ,b\) and equating them to zero gives
Substituting the result back to the dual problem gives
Solving this quadratic program with linear constraints yields \(\boldsymbol{\lambda} ^*\).
Besides, due to strong duality, KKT conditions hold, such that
which gives \(b^* = y_k - \boldsymbol{w} ^{* \top} \boldsymbol{x} _k\). Therefore,
Properties¶
The weights is a linear combination of data vectors
where \(\lambda_i \ne 0\) for the points that lies on the margin, i.e. only the data on the margin defines \(\boldsymbol{w}^*\).
Moreover,
If \(\boldsymbol{w}^{* \top} \boldsymbol{x} + b^* = \pm 1\) then the point lie on the hyperplane \(\pm\) margin. The vector \(\boldsymbol{x}\) is called a support vector.
If \(\left\vert \boldsymbol{w}^{* \top} \boldsymbol{x} + b^* \right\vert < 1\) then the point lie inside the two margins.
If \(\left\vert \boldsymbol{w}^{* \top} \boldsymbol{x} + b^* \right\vert > 1\) then the point lie outside the two margins.
If we add more such points to the data set (with correct labels) and re-run SVM, then the solution is the same, since they do not affect \(\min _{i} \frac{1}{|\boldsymbol{w}|} y_{i} \left( \boldsymbol{w} ^ {\top} \boldsymbol{x}_{i}+b\right)\) in the objective function.
maximized margin is
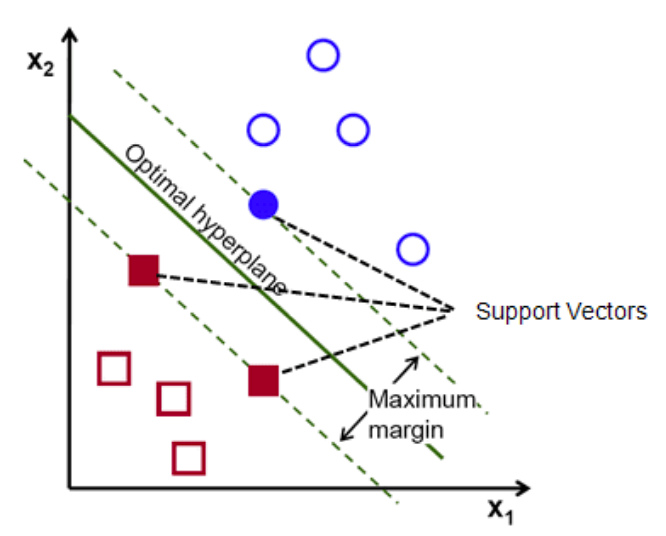
Fig. 86 Support vectors¶
Extension¶
Multiclass¶
One-versus-rest: construct \(K\) separate SVMs. Using \(k^*=\arg \max _{k} (\boldsymbol{w}_k ^\top \boldsymbol{x} + b_k)\)
One-versus-one: construct \(\frac{K(K-1)}{2}\) SVMs on all pairs. Each SVM classifies a point to either \(k_1\) or \(k_2\). For prediction, select \(k\) with the highest votes.
“True” multi-class SVMs (Crammer and Singer, 2001)
Soft Margin¶
Recall the objective function for the hard margin case
What if we cannot find a hyperplane that separate the two types of points? That is, the constraint
does not hold for all \(i\). Some observation will violate this constraint.
In such case, we can add a loss term to measure the extent of violation, and include this loss into the objective function. This kind of margin is called soft margin.
The new objective function becomes
where
\(R\) is some loss function.
\(C\) is a parameter to control the weight on the loss term. When \(C\rightarrow \infty\), the formulation approaches separable case.
For instance, \(R\) can be an indicator function, with value \(1\) if the constraint is violated, i.e.
A more reasonable loss is to measure the actual deviation from the constrain, i.e., \(1 - y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right)\), for those who violates the constraint, i.e. \(y_{i}\left(\boldsymbol{w}^{\top} \boldsymbol{x}_{i}+b\right) < 1\). Overall, the loss function is
which is called Hinge loss.
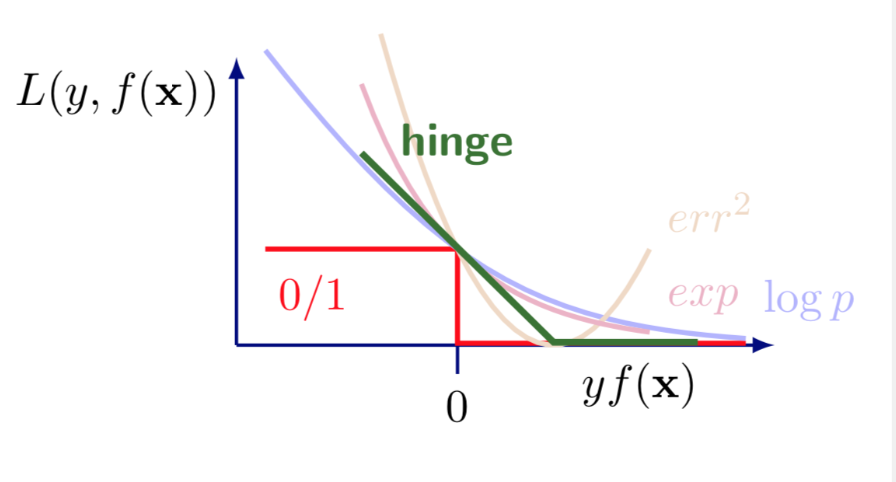
Fig. 87 Comparison of loss functions¶
Let \(\xi_{i}=\max \left\{0,1-y_{i}\left(\boldsymbol{w}^{\top} x_{i}+w_{0}\right)\right\}\), then the objective is
From optimization point of view \(\xi_i\) is called a slack variable.
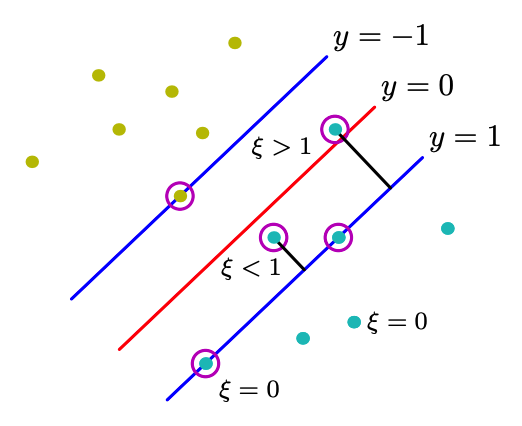
Fig. 88 Hinge loss of data points [Bishop]¶
Applying similar conversion to the basic case above, we get
This can be solved by gradient descent.
Kernel SVMs¶
If the points are non-seperable, we consider transform them into a higher-dimensional space by a feature transformation \(\boldsymbol{\boldsymbol{\phi}}(\boldsymbol{x})\), and find a hyperplane there to separate the points (hopefully).
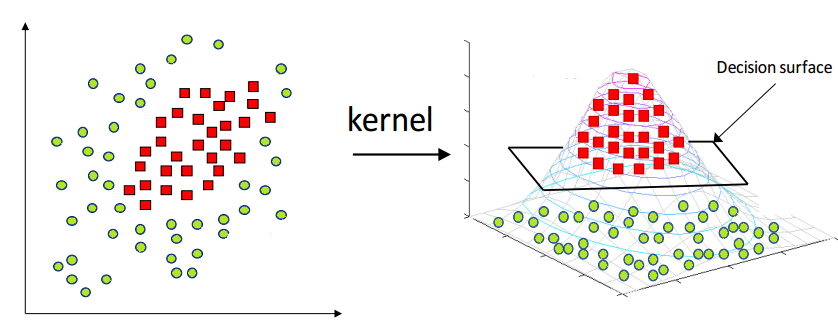
Fig. 89 SVM Kernel trick¶
Transformed Unconstrained Original¶
For the original problem, after transformation into \(\boldsymbol{\phi}(\boldsymbol{x})\) it becomes
By the Representer Theorem and some refinement, the optimal solution has the form
Substituting it back to the objective function gives
and
So we turn \(\mathcal{L}\left(\boldsymbol{w}, w_{0}\right)\) to \(\mathcal{L}\left(\boldsymbol{\alpha} , w_{0}\right)\) and we can then solve it by SGD.
Transformed Dual¶
The primal problem becomes
and the dual problem becomes
We find there is a dot product in the objective function, so we can consider using a PSD kernel \(k(\boldsymbol{x} , \boldsymbol{y} )=\boldsymbol{\phi}(\boldsymbol{x} )^{\top} \boldsymbol{\phi}(\boldsymbol{y} )\). The problem becomes
and we solve the QP problem for \(\boldsymbol{\alpha}\).
Pros and Cons¶
Pros
Based on a theoretical model of learning explicitly, with guaranteed performance.
Not affected by local minima.
Do not suffer from the curse of dimensionality.
Quadratic program, doable.
Optimization algorithm instead of greedy search.
Integrated into other high performers such as deep neural networks.
Kernel trick
Cons
Do not directly output probablitity, only scores
there are some methods to output class membership probability estimates, e.g. Platt scaling, which use logistic regression on the output scores and cross-validation. see here.